字符串:KMP、trie树、哈希表
字符串:KMP、trie树、哈希表
KMP
一、什么是KMP
KMP算法是一种字符串匹配算法,可以在 O(n+m) 的时间复杂度内实现两个字符串的匹配。
以下算法分析的内容转载自:阮行止的博客
一些解释:原文作者的字符数组下标是从0开始的,因此图片和修改后的文字可能会有一些不符,代码模板中用的是i 与 j+1位相比较,因此 j=nxt[j] 处的 j 不需要减去1.
二、字符串匹配问题
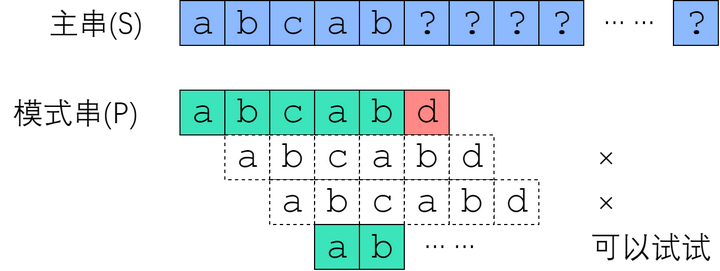
所谓字符串匹配,是这样一种问题:“字符串 P 是否为字符串 S 的子串?如果是,它出现在 S 的哪些位置?” 其中 S 称为主串;P 称为模式串。下面的图片展示了一个例子。
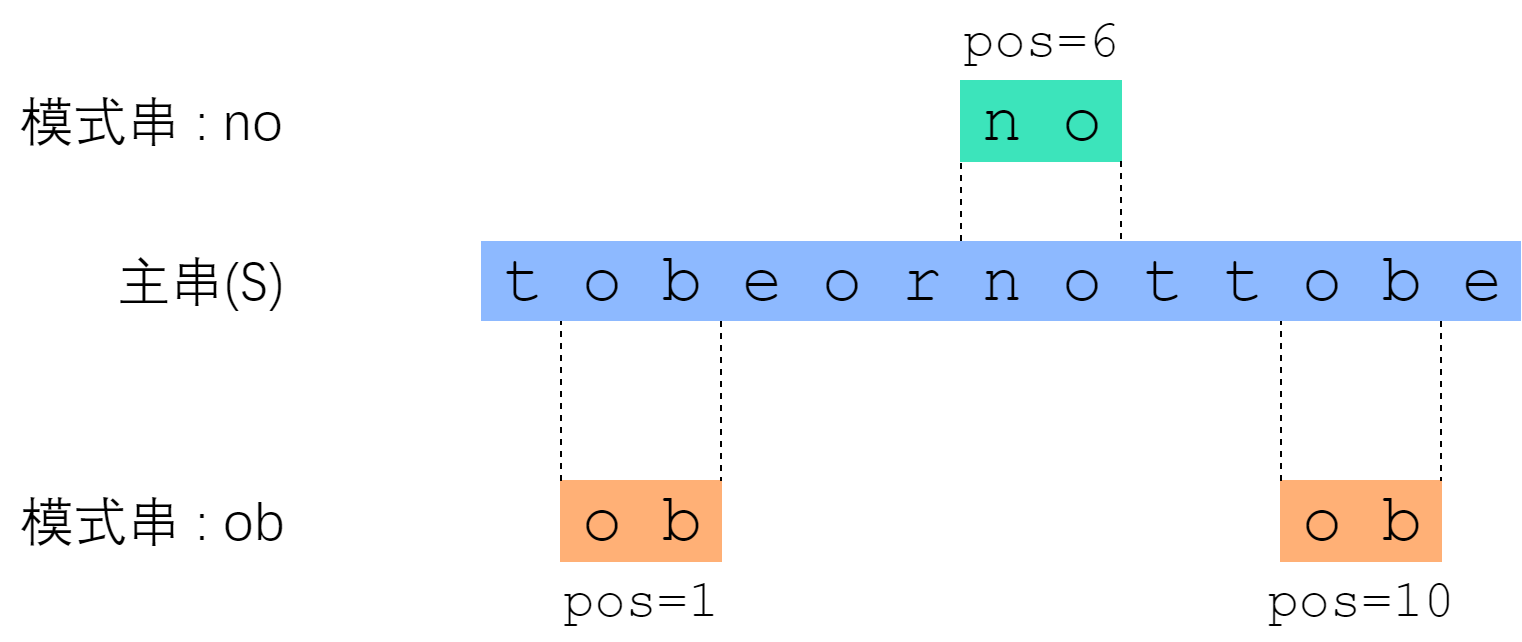
三、KMP算法:
一、暴力做法:
时间复杂度O($$n^2$$)
1 | for(int i=1;i<=len_s;i++) |
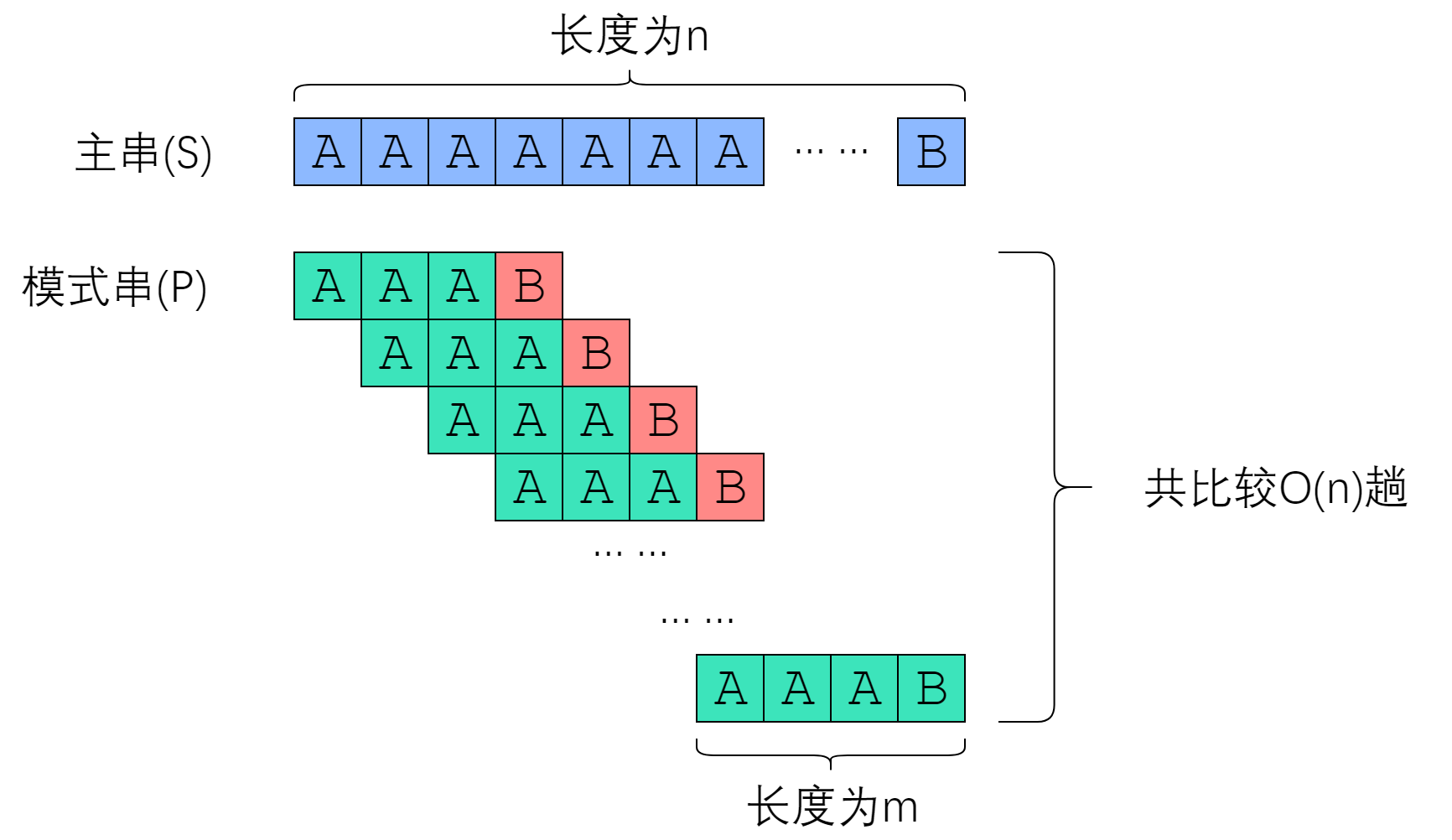
二、改进思路
我们很难降低字符串比较的复杂度(因为比较两个字符串,真的只能逐个比较字符)。因此,我们考虑降低比较的趟数。如果比较的趟数能降到足够低,那么总的复杂度也将会下降很多。要优化一个算法,首先要回答的问题是“我手上有什么信息?” 我们手上的信息是否足够、是否有效,决定了我们能把算法优化到何种程度。请记住:尽可能利用残余的信息,是KMP算法的思想所在。
稍微模拟一下暴力做法可以发现,我们在匹配的过程中,模式串(短串)是没有必要慢慢爬过去的。在暴力做法中,如果从 S[i] 开始的那一趟比较失败了,算法会直接开始尝试从 S[i+1] 开始比较。这种行为,属于典型的“没有从之前的错误中学到东西”。我们应当注意到,一次失败的匹配,会给我们提供宝贵的信息——如果 S[i : i+len(P)] 与 P 的匹配是在第 r 个位置失败的,那么从 S[i] 开始的 (r-1) 个连续字符,一定与 P 的前 (r-1) 个字符一模一样!
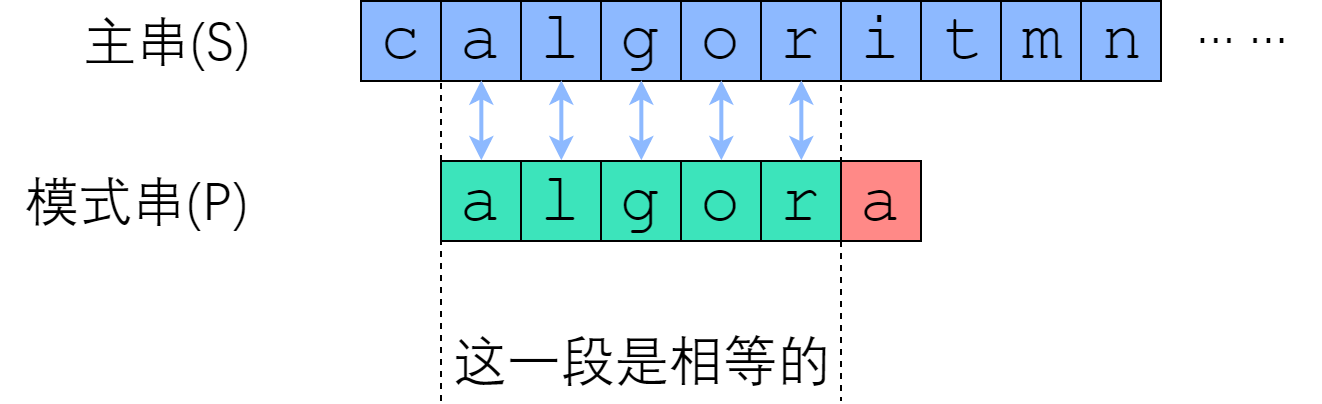
需要实现的任务是“字符串匹配”,而每一次失败都会给我们换来一些信息——能告诉我们,主串的某一个子串等于模式串的某一个前缀。但是这又有什么用呢?
三、跳过不可能成功的字符串比较
有些趟字符串比较是有可能会成功的;有些则毫无可能。我们刚刚提到过,优化暴力做法的路线是“尽量减少比较的趟数”,而如果我们跳过那些绝不可能成功的字符串比较,则可以希望复杂度降低到能接受的范围。
那么,哪些字符串比较是不可能成功的?来看一个例子。已知信息如下:
- 模式串 P = “abcabd”.
- 和主串从S[1]开始匹配时,在 P[6] 处失配。
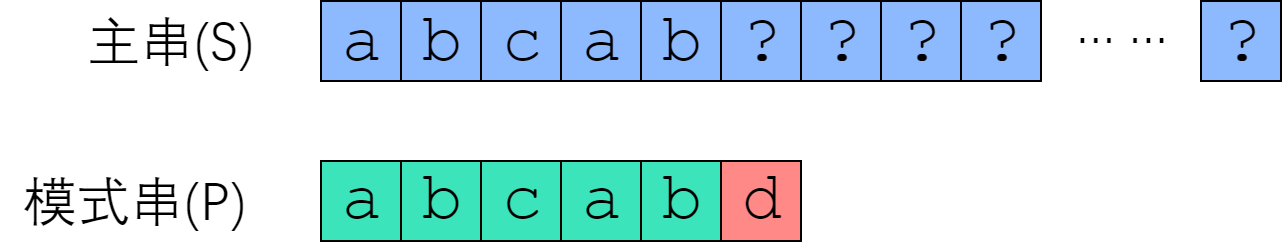
首先,利用上一节的结论。既然是在 P[6] 失配的,那么说明 S[1-5] 等于 P[1-5],即”abcab”. 现在我们来考虑:从 S[2]、S[3]、S[4] 开始的匹配尝试,有没有可能成功?
从 S[2] 开始肯定没办法成功,因为 S[2] = P[2] = ‘b’,和 P[1] 并不相等。从 S[3] 开始也是没戏的,因为 S[3] = P[3] = ‘c’,并不等于P[1]. 但是从 S[4] 开始是有可能成功的——至少按照已知的信息,我们推不出矛盾。
带着“跳过不可能成功的尝试”的思想,我们来看next数组。
四、next数组的介绍
next数组是对于模式串而言的。
定义:模式串P 的 next 数组定义为:next[i] 表示 P[1] ~ P[i] 这一个子串,使得 前k个字符 恰等于 后k个字符 的最大的k。 特别地,k不能取i(因为这个子串一共才 i 个字符,自己肯定与自己相等,就没有意义了)。 p[1,k]=p[i-k+1,i]
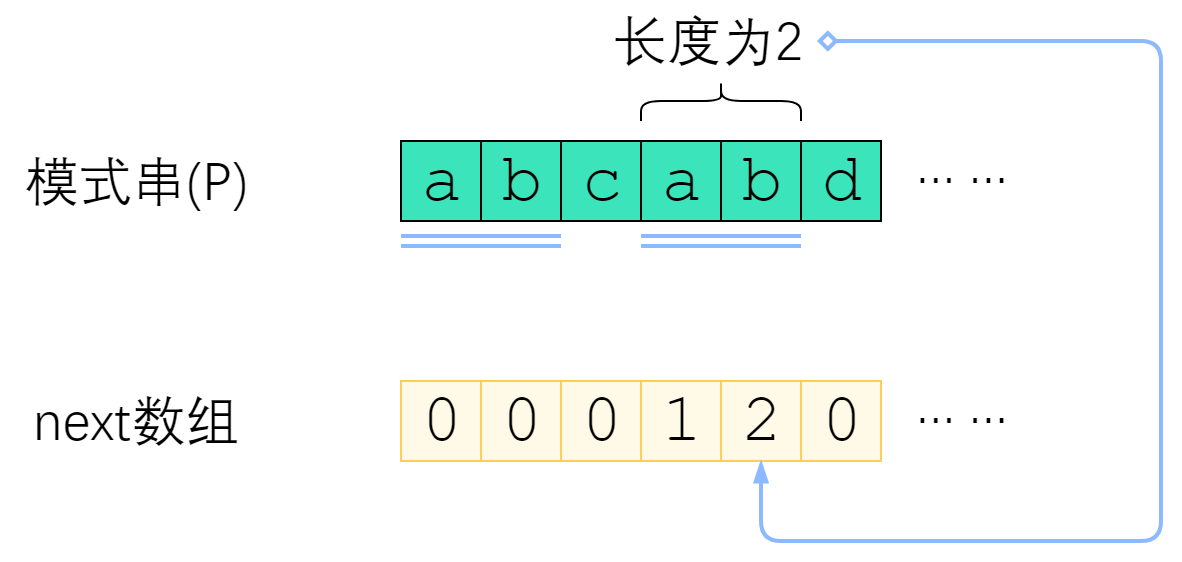
上图给出了一个例子。P=”abcabd”时,next[5]=2,这是因为P[1] ~ P[5] 这个子串是”abcab”,前两个字符与后两个字符相等,因此next[5]取2. 而next[6]=0,是因为”abcabd”找不到前缀与后缀相同,因此只能取0。
如果把模式串视为一把标尺,在主串上移动,那么 暴力做法 就是每次失配之后只右移一位;
改进算法则是每次失配之后,移很多位,跳过那些不可能匹配成功的位置。但是该如何确定要移多少位呢?
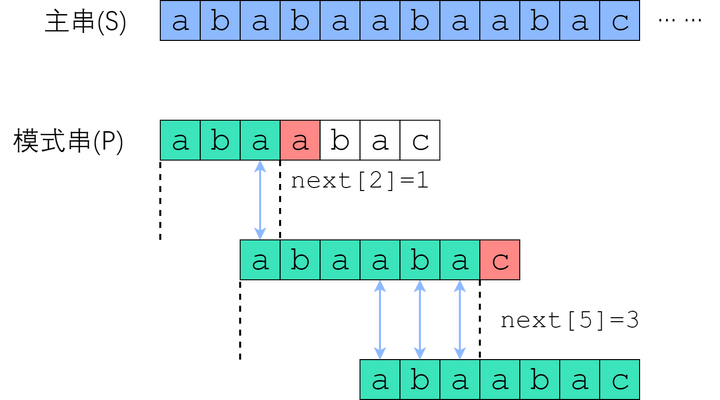
在 S[1] 尝试匹配,失配于 S[4] <=> P[4] 之后,我们直接把模式串往右移了两位,让 S[3] 对准 P[1]. 接着继续匹配,失配于 S[9] <=> P[7], 接下来我们把 P 往右平移了三位,把 S[9] 对准 P[4]。此后继续匹配直到成功。
(按照我的写法,图中应为next[3]=1, next[6]=3)
我们应该如何移动这把标尺?很明显,如图中蓝色箭头所示,旧的后缀要与新的前缀一致(如果不一致,那就肯定没法匹配上了)!
回忆next数组的性质:P[1] 到 P[i] 这一段子串中,前next[i]个字符与后next[i]个字符一模一样。既然如此,如果失配在 P[r], 那么P[1]~P[r-1]这一段里面,前next[r-1]个字符恰好和后next[r-1]个字符相等——也就是说,我们可以拿长度为 next[r-1] 的那一段前缀,来顶替当前后缀的位置,让匹配继续下去!
您可以验证一下上面的匹配例子:P[4]失配后,把P[next[4-1]]也就是P[1]对准了主串刚刚失配的那一位;P[7]失配后,把P[next[7-1]]也就是P[4]对准了主串刚刚失配的那一位。
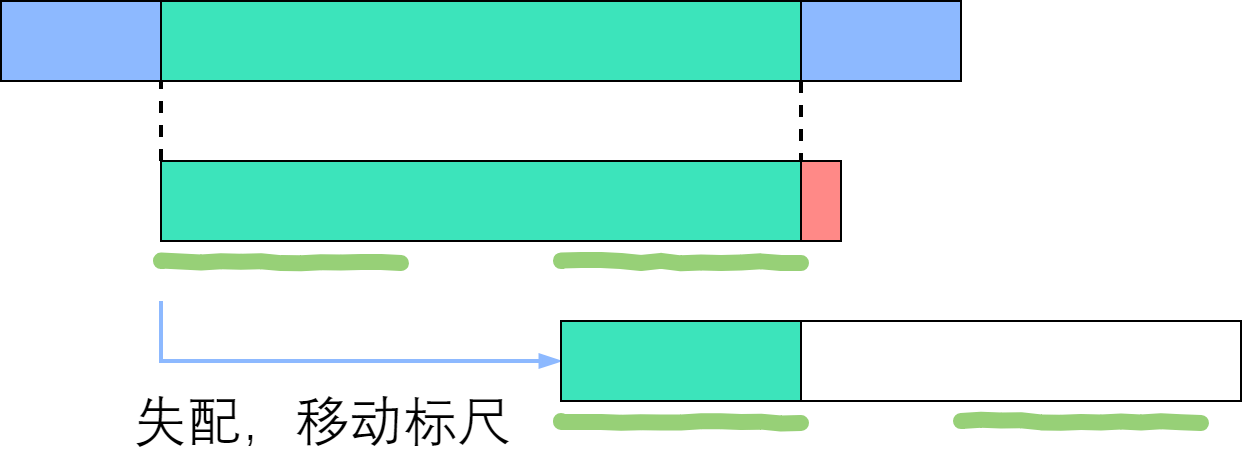
如上图所示,绿色部分是成功匹配,失配于红色部分。深绿色手绘线条标出了相等的前缀和后缀,其长度为next[右端]. 由于手绘线条部分的字符是一样的,所以直接把前面那条移到后面那条的位置。因此说,next数组为我们如何移动标尺提供了依据。接下来,我们实现这个优化的算法。
五、利用next数组进行匹配
代码实现
1 | for(int i=1,j=0;i<=len_s;i++) |
六、求出next数组
终于来到了我们最后一个问题——如何快速构建next数组。
首先说一句:快速构建next数组,是KMP算法的精髓所在,核心思想是“P自己与自己做匹配”。
为什么这样说呢?回顾next数组的完整定义:
- 定义 “k-前缀” 为一个字符串的前 k 个字符; “k-后缀” 为一个字符串的后 k 个字符。k 必须小于字符串长度。
- next[x] 定义为: P[0]~P[x] 这一段字符串,使得k-前缀恰等于k-后缀的最大的k.
这个定义中,不知不觉地就包含了一个匹配——前缀和后缀相等。接下来,我们考虑采用递推的方式求出next数组。如果next[1], next[2], … next[x-1]均已知,那么如何求出 next[x] 呢?
分情况讨论。首先,已经知道了 next[x-1](以下记为now),如果 P[x] 与 P[now] 一样,那最长相等前后缀的长度就可以扩展一位,很明显 next[x] = now + 1. 图示如下。
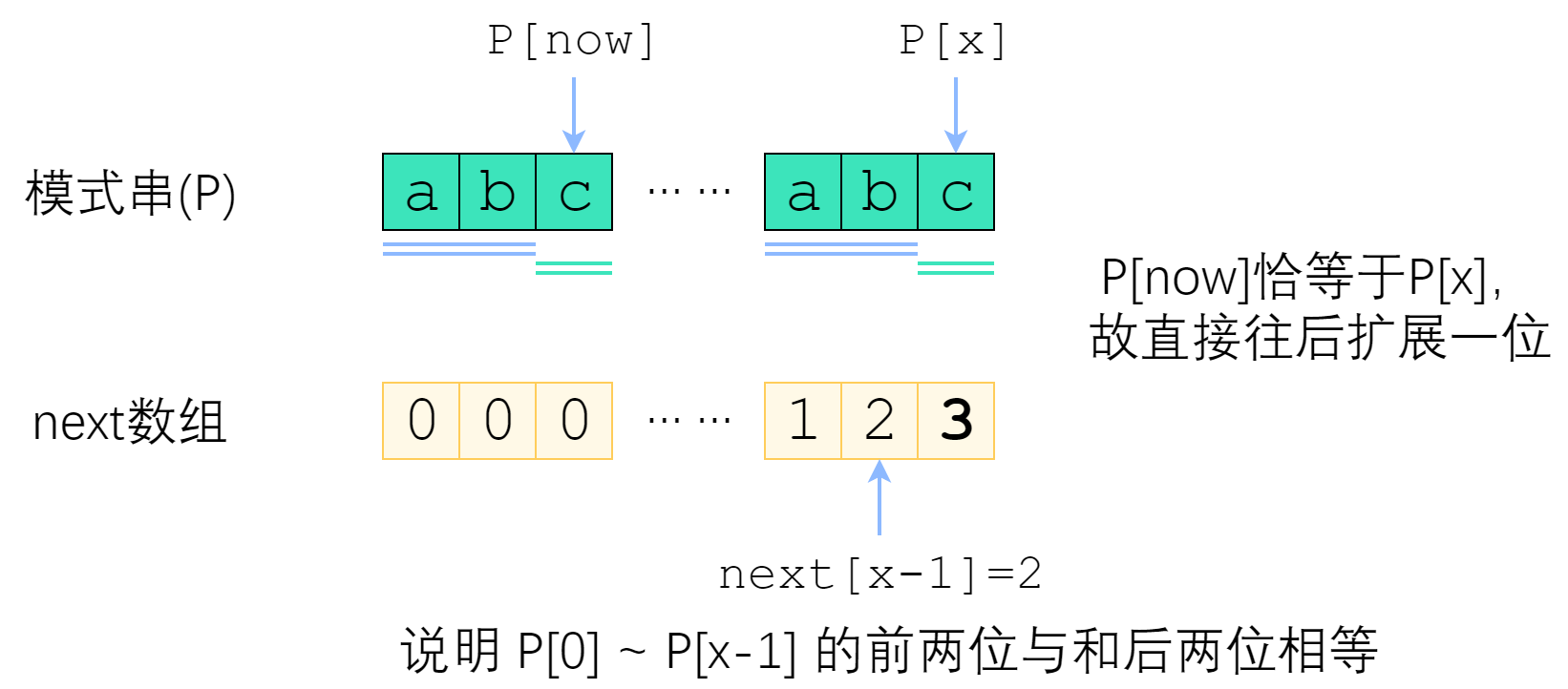
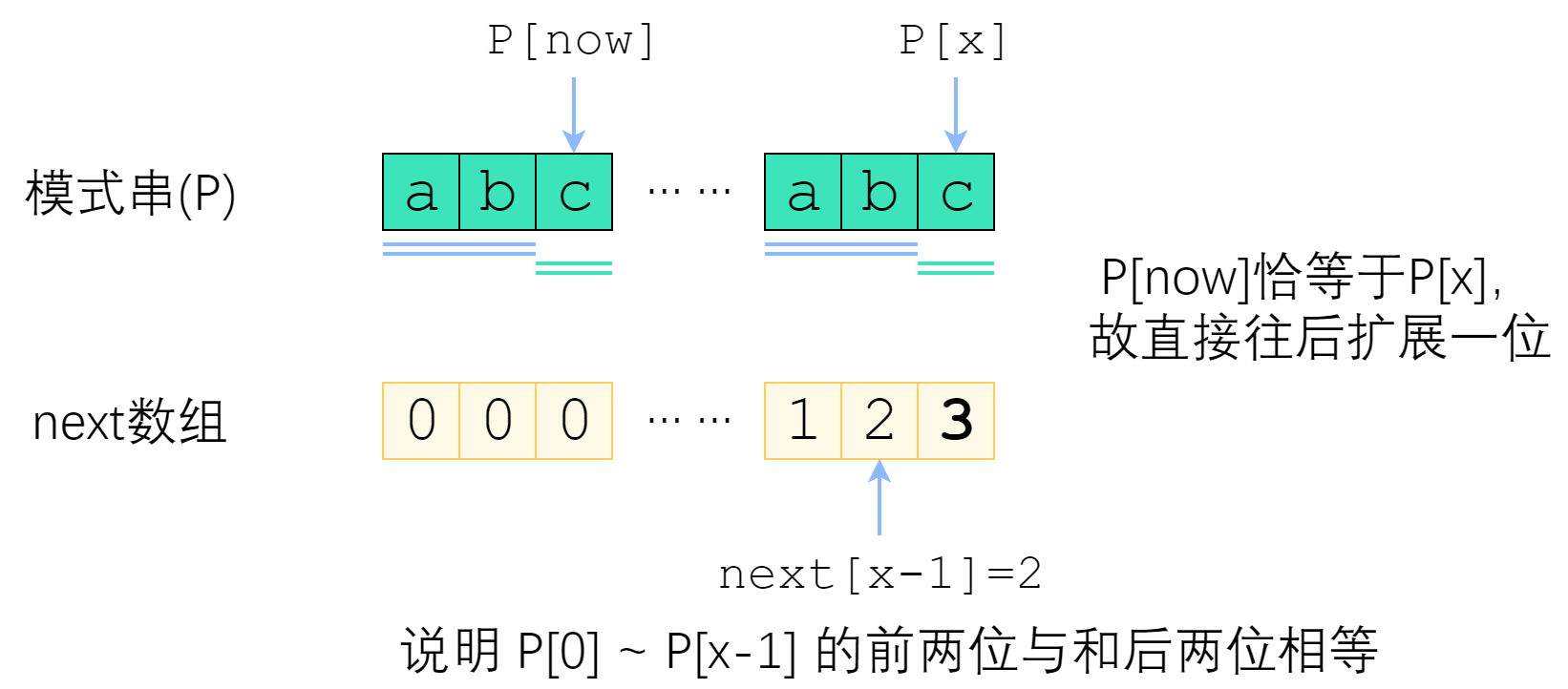
刚刚解决了 P[x] = P[now] 的情况。那如果 P[x] 与 P[now] 不一样,又该怎么办?
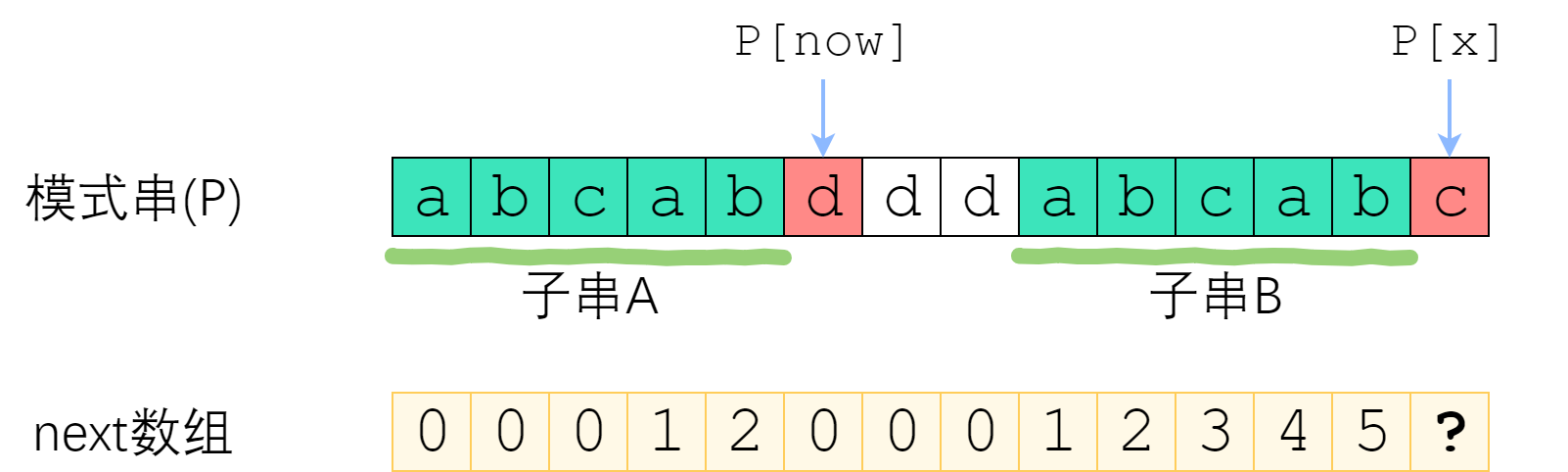
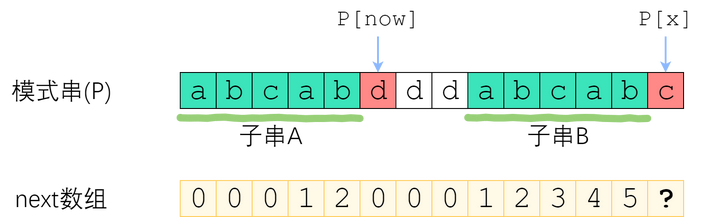
如图。长度为 now 的子串 A 和子串 B 是 P[1]P[x-1] 中最长的公共前后缀。可惜 A 右边的字符和 B 右边的那个字符不相等,next[x]不能改成 now+1 了。因此,我们应该缩短这个now,把它改成小一点的值,再来试试 P[x] 是否等于 P[now].P[x-1]的now-前缀仍然等于now-后缀”的前提下,让这个新的now尽可能大一点。 P[0]~P[x-1] 的公共前后缀,前缀一定落在串A里面、后缀一定落在串B里面。换句话讲:接下来now应该改成:使得 A的k-前缀等于B的k-后缀 的最大的k.
now该缩小到多少呢?显然,我们不想让now缩小太多。因此我们决定,在保持“P[0]
您应该已经注意到了一个非常强的性质——串A和串B是相同的!B的后缀等于A的后缀!因此,使得A的k-前缀等于B的k-后缀的最大的k,其实就是串A的最长公共前后缀的长度 —— next[now-1]!
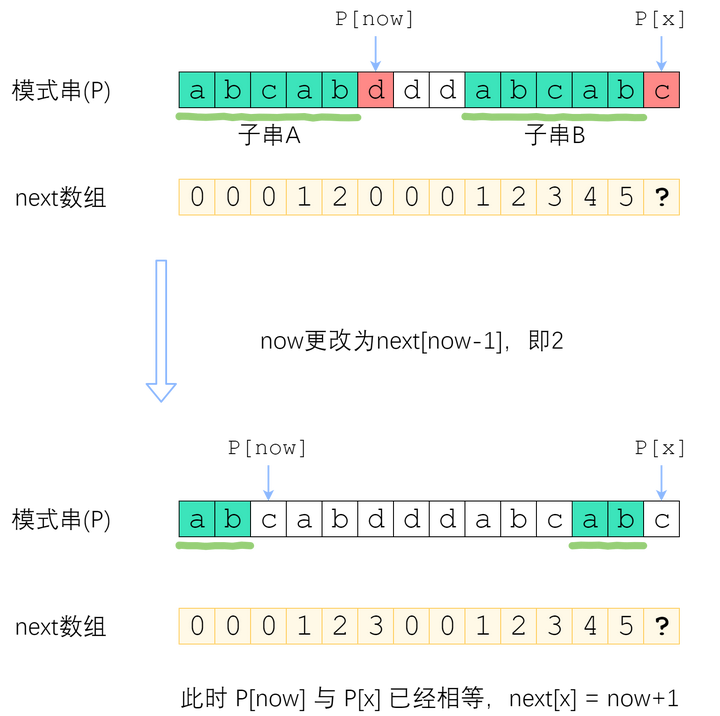
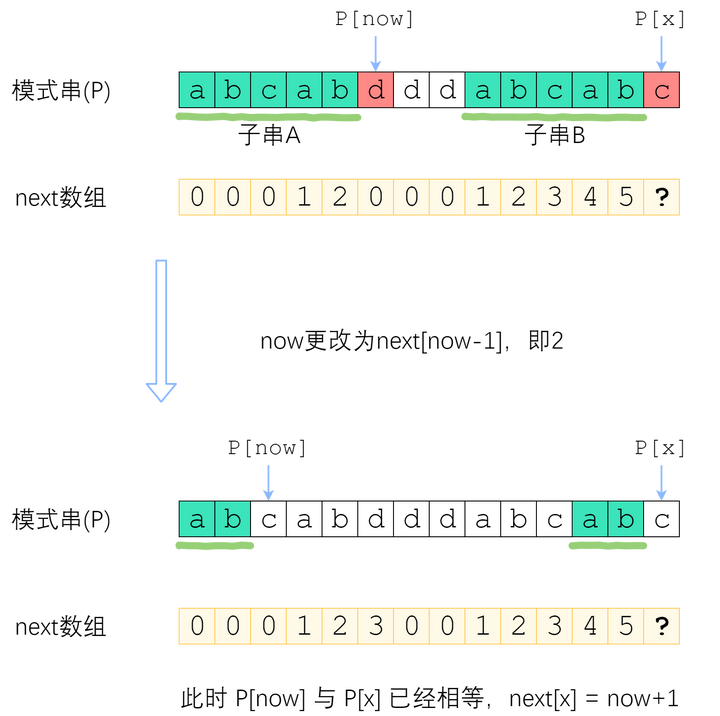
来看上面的例子。当P[now]与P[x]不相等的时候,我们需要缩小now——把now变成next[now-1],直到P[now]=P[x]为止。P[now]=P[x]时,就可以直接向右扩展了。
代码实现
1 | for(int i=2,j=0;i<=len_p;i++) |
复杂度分析(五、六步相同,这里以六为例):每次循环有m=len_p 次,j每次for循环中最多+1,在while中最多减m=len_p 次,因此复杂度为O(2*len_p),即O(N)的线性复杂度。
四、例题+完整模板
acwing831. KMP字符串
给定一个模式串S,以及一个模板串P,所有字符串中只包含大小写英文字母以及阿拉伯数字。
模板串P在模式串S中多次作为子串出现。
求出模板串P在模式串S中所有出现的位置的起始下标。
输入格式
第一行输入整数N,表示字符串P的长度。
第二行输入字符串P。
第三行输入整数M,表示字符串S的长度。
第四行输入字符串S。
输出格式
共一行,输出所有出现位置的起始下标(下标从0开始计数),整数之间用空格隔开。
数据范围
1≤N≤$10^5$
1≤M≤$$10^6$$
输入样例:
1 | 3 |
输出样例:
1 | 0 2 |
代码
1 |
|
Trie 树
一、定义
Trie树又称字典树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
高效的 存储 和 查找 字符串集合的数据结构
二、例题+模板
1. acwing 835 .Trie字符串统计
维护一个字符串集合,支持两种操作:
- “I x”向集合中插入一个字符串x;
- “Q x”询问一个字符串在集合中出现了多少次。
共有N个操作,输入的字符串总长度不超过 $10^5$,字符串仅包含小写英文字母。
输入格式
第一行包含整数N,表示操作数。
接下来N行,每行包含一个操作指令,指令为”I x”或”Q x”中的一种。
输出格式
对于每个询问指令”Q x”,都要输出一个整数作为结果,表示x在集合中出现的次数。
每个结果占一行。
数据范围
1≤N≤$2∗10^4$
输入样例:
1 | 5 |
输出样例:
1 | 1 |
代码模板:
1 |
|
2. acwing 143. 最大异或对
在给定的N个整数$A_1,A_2……A_N$中选出两个进行xor(异或)运算,得到的结果最大是多少?
输入格式
第一行输入一个整数N。
第二行输入N个整数$A_1,A_2……A_N$。
输出格式
输出一个整数表示答案。
数据范围
1≤N≤$10^5$,
0≤Ai< 2^31
输入样例:
1 | 3 |
输出样例:
1 | 3 |
解析:
- 暴力做法,O($N^2$)枚举显然会超时,考虑优化到O($NlogN$) ,因为第一层枚举$a_i$很难省略掉,所以考虑减少第二层$a_j$枚举的时间
- 由于异或是对每一位二进制位按位来做,因此如果预处理出每一个数的每一位二进制位的话,就可以找出对于每一个数的最优匹配的数。(关于正确性证明:只要从高位开始枚举,那么选择高位相反(即最优匹配)的显然比选择低位相反的更优,因此可以贪心的考虑优先保证前面的位数)
代码:
1 |
|
哈希表
一、定义
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
模数一定取质数(冲突概率小)
二、处理哈希冲突
拉链法:对相同的哈希值,拉一条链(链表)来存储这些元素。一般情况下这些链的长度可视为常数,因此复杂度O(1)。
1 | /* |
开放取址法:
1 |
|
三、模板+例题
acwing841. 字符串哈希
给定一个长度为n的字符串,再给定m个询问,每个询问包含四个整数 l1,r1,l2,r2 。请你判断[l1,r1]和[l2,r2]这两个区间所包含的字符串子串是否完全相同。
字符串中只包含大小写英文字母和数字。
输入格式
第一行包含整数n和m,表示字符串长度和询问次数。
第二行包含一个长度为n的字符串,字符串中只包含大小写英文字母和数字。
接下来m行,每行包含四个整数l1,r1,l2,r2,表示一次询问所涉及的两个区间。
注意,字符串的位置从1开始编号。
输出格式
对于每个询问输出一个结果,如果两个字符串子串完全相同则输出“Yes”,否则输出“No”。
每个结果占一行。
数据范围
1≤n,m≤10^5
输入样例:
1 | 8 3 |
输出样例:
1 | Yes |
代码:
1 |
|
洛谷P3370【模板】字符串哈希
题目描述
如题,给定 N个字符串(第 i个字符串长度为 M_i,字符串内包含数字、大小写字母,大小写敏感),请求出 N 个字符串中共有多少个不同的字符串。
输入格式
第一行包含一个整数 N,为字符串的个数。
接下来 N行每行包含一个字符串,为所提供的字符串。
输出格式
输出包含一行,包含一个整数,为不同的字符串个数。
输入输出样例
输入 #1
1 | 5 |
输出 #1
1 | 4 |
本题方法多样,哈希,字典树,善用STL中的set或unique,或者直接利用string的大小于号来排序都可以做。(这里已经讲了4种了QAQ)
哈希做法:
1 |
|